




What keeps a gazelle awake at night? It might be the thought of the “Lurking Latent Crocodiles” that inhabit the rivers and waterholes waiting to pounce without warning. What if your life as a gazelle was not to visit the waterhole only once a day, or cross a river only during a long migration? What if it was to walk 24*7 up the middle of the crocodile infested river? That would surely keep you alert, yet not comfortable, and only able to sleep restlessly for very short periods of time.
If living in the river is your life, then it would be in your interest as a gazelle to keep crocodile numbers as low as possible, and to not expose yourself to the chances of being caught by lingering on the edge of the herd.
Herd Instinct
Being in the middle of the herd is important to survival. We recognize the effect of this survival instinct when a company releases a new operating system. The early adopters will load it and play with it, but few will immediately use it as a core business tool. The clever gazelles wait until the waters have been tested first. Clever gazelles also know to keep up and not become stragglers. We know of applications still in mission–critical production that the vendor ceased support for many years ago.
How do people accidentally find themselves on the edge of the herd?
Forging ahead without clear risk management:
- Loading newly released and untested code onto production equipment
- Installing and commissioning untested, just released hardware into a production environment
- Loading production workload onto untested configurations
- Emergency change controls during shotgun style troubleshooting
Getting behind by not changing current systems:
- Using core business software which is no longer supported
- Using hardware in production that is unsupported
Configuring exotic solutions:
- System integrating hardware and software to make the system a one of a kind
- Changing core code to make the system unique
Configuring exotic loads or profiles:
- Overworking the system beyond its capabilities
- Extreme tuning of software and firmware parameters for a given application
- Reaching a saturation point where the system moves from linear flow to turbulence
Diagram 1
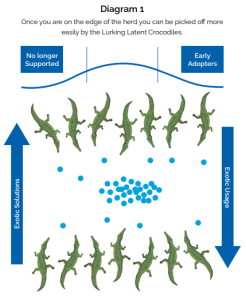
Once you are on the edge of the herd you can be picked off more easily by the Lurking Latent Crocodiles.
Pest Control
When a computer technician reformatted a disk drive at the Alaska Department of Revenue while performing routine maintenance work, a small miracle of the bad sort occurred. The technician accidentally deleted applicant information for an oil-funded account — one of Alaska residents’ biggest perks — and mistakenly reformatted the backup drive, as well.
There was still hope, until the department discovered its third line of defense, backup tapes, were unreadable. Had the backup tapes worked, there would be no story – in this case, there is no mention of whether they already had any known and un-solved issues with the backup system – but have you checked that you can restore your data? This failure cost them $200,000 in additional costs and unknown reputation damage. Is there a latent lurking crocodile waiting for you?
Just being in the middle of the herd – doing the same sort of things that other companies are doing, using standard configurations and standard software, keeping it up to date and within performance tolerances – is still no guarantee of survival.
The very worst IT incidents we see as Kepner-Tregoe consultants are a combination of a number of latent, visible and undiagnosed problems and poorly completed changes which have conspired to cause a miracle. Often miracles are considered an amazing or wonderful occurrence. I speculate that to bring together the undiagnosed problems in just such a way as to cause a catastrophic failure can also be miraculous, just in a bad way.
Let me take the example of a Fortune 500 global company who use IT systems like everyone else does: to receive orders, plan manufacturing, schedule deliveries and issue invoices on current hardware and very popular software. The IT department lost the ability to know what to manufacture, ship and invoice for about three weeks. The incident did not reach the media as it was handled well and the company continues to thrive. However, during those three weeks the “Crocodiles” were in the middle of the gazelles and had acted in uncoordinated concert to bring the core business IT systems down.
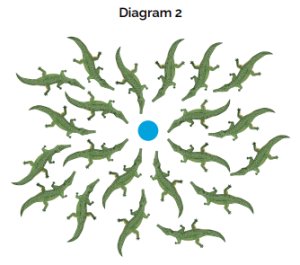
Can we predict the likelihood of the Latent Lurking Crocodiles taking your business out? If you were a gazelle walking in the middle of the river, surrounded by other gazelles, some out front, some lagging behind, some near the left bank of the river and some near the right, would you prefer to be walking up a river with a lot of crocodiles or a very few?
Pest control to reduce the number of Crocodiles would simply reduce the number of opportunities for them to mindlessly conspire to hurt you. Where do we find these Crocodiles? … in your undiagnosed backlog of IT problems.
The higher the number of undiagnosed IT problems you have, the higher the opportunity for one, or two, or many to interact in some interesting way, with an innocent change, to bring your system down. Companies where the root causes for IT problems are generally found have a mathematically better chance of IT survival than those with large numbers of undiagnosed problems: problems that are both lurking (you know about them – they are in a queue somewhere, or they are in a mass of uncontrolled changes or hiding in poor housekeeping) and latent (not affecting production at the moment).
Let me be specific about the kinds of problems that can randomly come together to cause prolonged IT outages.
Let us say that you were making a change to the number of products your infrastructure was planning to process because you bought another company and needed to integrate their product lines.
You worked with the suppliers to specify the hardware and software that was required, and a project plan was created to implement the change. Change management was on board, all was good.
What you did not know is that buried deeply in your backlog of undiagnosed problems were four faults with the production system, none of which were causing production problems and so were not in the minds of the support staff:
- A slow database queue processing job for the past six months
- Slow logical input/output to your shared data storage device on other systems not obviously related to this one – a problem logged with another part of the infrastructure organisation several weeks ago
- A firmware upgrade to the data storage interconnect that did not apply correctly some weeks ago
- Database monitoring tools that for the past year had occasionally stopped recording
These problems had been logged, and they were awaiting some action by either on the supplier or your staff.
You then add the software upgrade and the required hardware to improve the performance of the system to give you some processing overhead. This change works perfectly (from their change management point of view); the system resumes production but no one checks the performance overhead that the application of the change was expected to produce. This is a very big Crocodile.
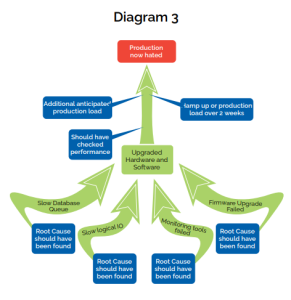
You then add the increased load to the system one factory at a time (just to make sure that each step is good). Some two weeks after beginning this process a ‘tipping point’ is reached, and the system flips from ‘free flow’ to turbulence – from taking 20 hours to process one day’s worth of work to 60 hours per day. The business managers begin screaming that the business is dying. You have to sever many factories from the batch jobs and reschedule production runs from every day to once a week. Some depots have to invent from experience what customers are likely to want to order from previous orders and the business is only maintained by heroic actions from huge numbers of staff who are running the business without your systems.
Returning to the previous configuration is only possible if the business is prepared to lose two weeks’ worth of invoices. The decision is made to forge forward using the new configuration, and during that process the Latent Lurking Crocodiles are discovered.
Not all of the Crocodiles were immediately malicious – the database monitoring tool had simply stopped two weeks before, and so the problem solving effort was extended by the lack of that information.
Lurking Latent Crocodiles are out there, waiting, unobserved, to come together into a single event that has the potential to be catastrophic.
How to survive
Clearly there are lessons to be learned from other people’s mistakes. Staying in middle of the IT crowd is a strategic IT decision for you and your customers to make: either stay safe or live an ‘interesting’ life.
But about reducing the likelihood of the undiagnosed faults conspiring against you? How many undiagnosed cases are in your IT support desk backlog? If you are clearing them away quickly and effectively, and if you have plans to handle the interim fixes and the corrective actions for the ones that are genuinely hard to solve, all is well.
If you have a large number of problems in your backlog, or have routinely closed their oldest cases just to keep the backlog a manageable size, you are lining your future with crocodiles.
In our engagements with clients who initially have a large backlog, we work with them to perform an analysis of the current state, calculate anticipated savings in terms of time and money, identify leverage points, and complete a structured and well–managed implementation of good quality case handling processes. Not only do they have a better support organisation, with more effective work processes and more highly motivated engineers, but they also sleep more soundly at night, knowing that there are fewer Lurking Crocodiles waiting to pounce without warning.
About Kepner-Tregoe
Kepner-Tregoe is the leader in problem-solving. For over six decades, Kepner-Tregoe has helped thousands of organizations worldwide solve millions of problems through more effective root cause analysis and decision-making skills. Kepner-Tregoe partners with organizations to significantly reduce cost and improve operational performance through problem-solving training, technology and consulting services.