




Response to the CrowdStrike Falcon Sensor Crash Incident Report using the Kepner-Tregoe Incident Mapping Approach
1. Identifying specific problems, their causes, and consequences
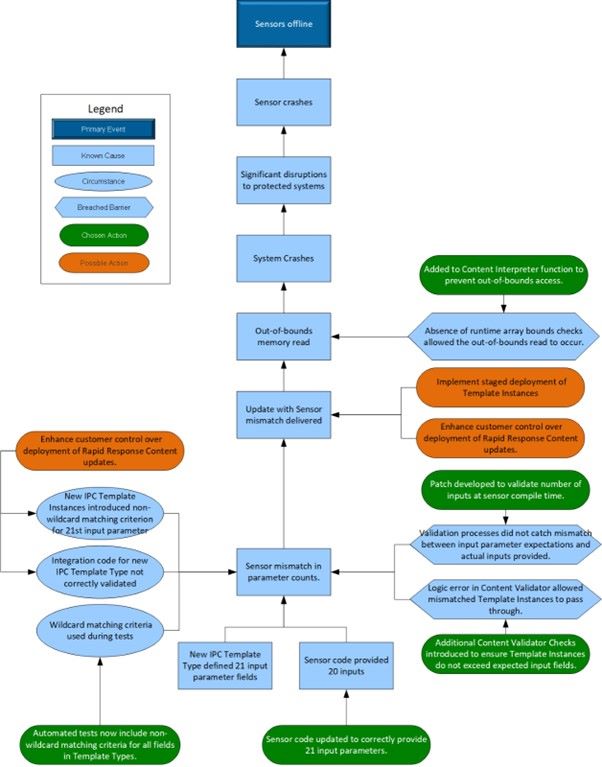
Problem: CrowdStrike Falcon sensor crash due to a mismatch in input parameters provided to the Content Interpreter from Channel File 291. Per CrowdStrike:
In February 2024, CrowdStrike introduced a new sensor capability to enable visibility into possible novel attack techniques that may abuse certain Windows mechanisms. This capability pre-defined a set of fields for Rapid Response Content to gather data. As outlined in the RCA, this new sensor capability was developed and tested according to our standard software development processes.
On March 5, 2024, following a successful stress test, the first Rapid Response Content for Channel File 291 was released to production as part of a content configuration update, with three additional Rapid Response updates deployed between April 8, 2024 and April 24, 2024. These performed as expected in production.
On July 19, 2024, a Rapid Response Content update was delivered to certain Windows hosts, evolving the new capability first released in February 2024. The sensor expected 20 input fields, while the update provided 21 input fields. In this instance, the mismatch resulted in an out-of-bounds memory read, causing a system crash. Our analysis, together with a third-party review, confirmed this bug is not exploitable by a threat actor.
Cause: The new IPC Template Type defined 21 input parameter fields, but only 20 inputs were provided by the sensor code. This mismatch led to an out-of-bounds memory read causing system crashes.
Consequences: This resulted in significant disruptions to the protected systems, leading to sensor crashes and potential vulnerabilities due to the sensors being offline. Parametrix, known for its cloud monitoring and insurance solutions, has pegged the total loss for the 25% of Fortune 500 companies affected (excluding Microsoft) at a staggering $5.4 billion. (source: CIO)
2. Determining the circumstances which contributed to the problem
Circumstances contributing to the problem:
- The integration code for the new IPC Template Type was not correctly validated, missing the mismatch in parameter counts.
- The issue evaded multiple layers of build validation and testing due to the use of wildcard matching criteria during tests.
- Deployment of new IPC Template Instances introduced the non-wildcard matching criterion for the 21st input parameter, triggering the mismatch issue.
3. Determining specific barriers which may have been breached or were not effective
Breached/non-effective barriers
- Development and testing processes: The validation processes did not catch the mismatch between the input parameter expectations and actual inputs provided.
- Content validator: The logic error in the content validator allowed the mismatched Template Instances to pass through.
- Bounds checking: The absence of runtime array bounds checks allowed the out-of-bounds read to occur.
4. Identifying Actions Taken and Proposed
Actions taken:
- Sensor Content Compiler Patch: A patch was developed to validate the number of inputs at sensor compile time.
- Runtime Array Bounds Check: Added to the Content Interpreter function to prevent out-of-bounds access.
- Template Type Update: The sensor code was updated to correctly provide the 21 input parameters
- Increased Testing Coverage: Automated tests now include non-wildcard matching criteria for all fields in Template Types.
- Content Validator Checks: Additional checks were introduced to ensure Template Instances do not exceed expected input fields.
Proposed Actions:
- Staged Deployment: Implementing staged deployment of Template Instances to identify potential issues before wider deployment.
- Customer Control: Enhancing customer control over the deployment of Rapid Response Content updates.
- Independent Review: Engaging third-party vendors to review the Falcon sensor code and the overall quality process.
Assessment of effectiveness in aligning with Kepner-Tregoe Process
The response to the incident has been effective in several areas according to the Kepner-Tregoe incident mapping process:
- Problem Identification: Clearly identified the root cause of the sensor crashes.
- Circumstances Determination: Thorough analysis of the contributing factors, including development, testing, and deployment processes.
- Barrier Identification: Successfully identified the gaps in the existing barriers, such as validation processes and bounds checking.
- Action Implementation: Implemented and proposed comprehensive mitigation actions to address the issues and prevent future occurrences.
However, there is room for improvement in ensuring more proactive measures and continuous monitoring to detect and address such issues earlier in the development and deployment lifecycle.
Recommended courses of action
1. Enhance validation and testing processes:
- Implement more rigorous testing scenarios that cover edge cases and non-wildcard criteria for all fields in Template Types.
- Introduce automated regression testing for each new Template Type and Template Instance to ensure compatibility and stability.
2. Strengthen deployment procedures:
- Establish a robust staged deployment process with incremental rollouts and thorough monitoring at each stage.
- Provide detailed telemetry and real-time feedback mechanisms to detect and mitigate issues quickly during deployment.
3. Improve development practices:
- Incorporate comprehensive code reviews and peer validations to identify potential integration issues early in the development cycle.
- Use static and dynamic analysis tools to detect parameter mismatches and other code anomalies automatically.
4. Increase customer involvement:
- Enhance customer control over Rapid Response Content updates, allowing them to opt in or out of specific updates based on their operational needs.
- Provide detailed release notes and impact assessments for each update to inform customers of potential risks and benefits.
5. Continuous improvement and monitoring
- Set up continuous improvement processes to regularly review and refine development, testing, and deployment practices.
- Establish ongoing monitoring and alerting systems to detect anomalies in real-time and initiate immediate corrective actions.
By adopting these recommendations, the organization can further align its incident response with Kepner-Tregoe methods, enhancing resilience and reducing the likelihood of similar incidents in the future. But if you want to build a robust environment that seeks to avoid these problems in the first place, contact us today.
Kepner-Tregoe Incident Map

