
Reaktion auf den CrowdStrike Falcon Sensor Crash Incident Report unter Verwendung des Kepner-Tregoe Incident Mapping Ansatzes
1. Identifizierung spezifischer Probleme, ihrer Ursachen und Folgen
Problem: CrowdStrike Falcon Sensor-Absturz aufgrund einer Diskrepanz bei den Eingabeparametern, die dem Content Interpreter von Channel File 291 bereitgestellt wurden. Laut CrowdStrike:
Im Februar 2024 führte CrowdStrike eine neue Sensor-Funktion ein, um Einblick in mögliche neuartige Angriffstechniken zu ermöglichen, die bestimmte Windows-Mechanismen missbrauchen könnten. Diese Funktion definierte vorab eine Reihe von Feldern für Rapid Response Content zur Datenerfassung. Wie in der RCA dargelegt, wurde diese neue Sensor-Funktion gemäß unseren standardmäßigen Softwareentwicklungsprozessen entwickelt und getestet.
Am 5. März 2024 wurde nach einem erfolgreichen Stresstest der erste Rapid Response Content für Channel File 291 im Rahmen einer Content-Konfigurationsaktualisierung in die Produktion freigegeben, wobei zwischen dem 8. April 2024 und dem 24. April 2024 drei weitere Rapid Response Updates bereitgestellt wurden. Diese funktionierten in der Produktion wie erwartet.
Am 19. Juli 2024 wurde ein Rapid Response Content Update an bestimmte Windows-Hosts ausgeliefert, das die im Februar 2024 erstmals veröffentlichte neue Funktion weiterentwickelte. Der Sensor erwartete 20 Eingabefelder, während das Update 21 Eingabefelder bereitstellte. In diesem Fall führte die Diskrepanz zu einem Out-of-Bounds-Speicherzugriff, der einen Systemabsturz verursachte. . Unsere Analyse bestätigte zusammen mit einer Überprüfung durch Dritte, dass dieser Fehler von einem Angreifer nicht ausgenutzt werden kann.
Ursache: Der neue IPC Template Type definierte 21 Eingabeparameterfelder, aber nur 20 Eingaben wurden vom Sensor-Code bereitgestellt. Diese Diskrepanz führte zu einem Out-of-Bounds-Speicherzugriff, der Systemabstürze verursachte.
Folgen: Dies führte zu erheblichen Störungen der geschützten Systeme, was zu Sensor-Abstürzen und potenziellen Schwachstellen aufgrund der Offline-Sensoren führte. Parametrix, bekannt für seine Cloud-Monitoring- und Versicherungslösungen, beziffert den Gesamtschaden für die 25 % der betroffenen Fortune-500-Unternehmen (ohne Microsoft) auf beachtliche 5,4 Milliarden US-Dollar. (Quelle: CIO)
2. Bestimmung der Umstände, die zum Problem beigetragen haben
Zum Problem beitragende Umstände:
- Der Integrationscode für den neuen IPC Template Type wurde nicht korrekt validiert, wodurch die Diskrepanz bei den Parameterzahlen übersehen wurde.
- Das Problem umging mehrere Ebenen der Build-Validierung und des Testens aufgrund der Verwendung von Wildcard-Matching-Kriterien während der Tests.
- Die Bereitstellung neuer IPC Template Instances führte das Nicht-Wildcard-Matching-Kriterium für den 21. Eingabeparameter ein, was das Diskrepanzproblem auslöste.
3. Bestimmung spezifischer Barrieren, die möglicherweise durchbrochen wurden oder nicht wirksam waren
Durchbrochene/nicht wirksame Barrieren
- Entwicklungs- und Testprozesse: Die Validierungsprozesse erkannten die Diskrepanz zwischen den Eingabeparametererwartungen und den tatsächlich bereitgestellten Eingaben nicht.
- Content Validator: Der Logikfehler im Content Validator ermöglichte es den nicht übereinstimmenden Template Instances, durchzukommen.
- Bounds Checking: Das Fehlen von Laufzeit-Array-Bounds-Checks ermöglichte den Out-of-Bounds-Zugriff.
4. Identifizierung ergriffener und vorgeschlagener Maßnahmen
Ergriffene Maßnahmen:
- Sensor Content Compiler Patch: Es wurde ein Patch entwickelt, um die Anzahl der Eingaben zur Sensor-Kompilierzeit zu validieren.
- Runtime Array Bounds Check: Zur Content Interpreter-Funktion hinzugefügt, um Out-of-Bounds-Zugriffe zu verhindern.
- Template Type Update: Der Sensor-Code wurde aktualisiert, um die 21 Eingabeparameter korrekt bereitzustellen.
- Erweiterte Testabdeckung: Automatisierte Tests umfassen nun Nicht-Wildcard-Matching-Kriterien für alle Felder in Template Types.
- Content Validator Checks: Zusätzliche Prüfungen wurden eingeführt, um sicherzustellen, dass Template Instances die erwarteten Eingabefelder nicht überschreiten.
Vorgeschlagene Maßnahmen:
- Stufenweise Bereitstellung: Implementierung einer stufenweisen Bereitstellung von Template Instances, um potenzielle Probleme vor einer breiteren Bereitstellung zu identifizieren.
- Kundenkontrolle: Verbesserung der Kundenkontrolle über die Bereitstellung von Rapid Response Content Updates.
- Unabhängige Überprüfung: Einbindung externer Anbieter zur Überprüfung des Falcon Sensor-Codes und des gesamten Qualitätsprozesses.
Bewertung der Wirksamkeit im Hinblick auf die Ausrichtung am Kepner-Tregoe-Prozess
Die Reaktion auf den Vorfall war in mehreren Bereichen gemäß dem Kepner-Tregoe Incident Mapping Prozess wirksam:
- Problemidentifizierung: Die Grundursache der Sensor-Abstürze wurde klar identifiziert.
- Umstandsbestimmung: Gründliche Analyse der beitragenden Faktoren, einschließlich Entwicklungs-, Test- und Bereitstellungsprozessen.
- Barrierenidentifizierung: Erfolgreiche Identifizierung der Lücken in den bestehenden Barrieren, wie Validierungsprozessen und Bounds Checking.
- Maßnahmenumsetzung: Umfassende Abhilfemaßnahmen wurden implementiert und vorgeschlagen, um die Probleme zu beheben und zukünftige Vorfälle zu verhindern.
Es besteht jedoch Verbesserungspotenzial bei der Gewährleistung proaktiverer Maßnahmen und kontinuierlicher Überwachung, um solche Probleme früher im Entwicklungs- und Bereitstellungszyklus zu erkennen und zu beheben.
Empfohlene Vorgehensweisen
1. Verbesserung der Validierungs- und Testprozesse:
- Implementierung strengerer Testszenarien, die Grenzfälle und Nicht-Wildcard-Kriterien für alle Felder in Template Types abdecken.
- Einführung automatisierter Regressionstests für jeden neuen Template Type und jede Template Instance, um Kompatibilität und Stabilität sicherzustellen.
2. Stärkung der Bereitstellungsverfahren:
- Etablierung eines robusten stufenweisen Bereitstellungsprozesses mit inkrementellen Rollouts und gründlicher Überwachung in jeder Phase.
- Bereitstellung detaillierter Telemetrie und Echtzeit-Feedback-Mechanismen, um Probleme während der Bereitstellung schnell zu erkennen und zu beheben.
3. Verbesserung der Entwicklungspraktiken:
- Einbeziehung umfassender Code-Reviews und Peer-Validierungen, um potenzielle Integrationsprobleme frühzeitig im Entwicklungszyklus zu identifizieren.
- Verwendung statischer und dynamischer Analysetools zur automatischen Erkennung von Parameterdiskrepanzen und anderen Code-Anomalien.
4. Verstärkte Kundeneinbindung:
- Verbesserung der Kundenkontrolle über Rapid Response Content Updates, sodass diese basierend auf ihren betrieblichen Anforderungen bestimmte Updates aktivieren oder deaktivieren können.
- Bereitstellung detaillierter Release Notes und Auswirkungsbewertungen für jedes Update, um Kunden über potenzielle Risiken und Vorteile zu informieren.
5. Kontinuierliche Verbesserung und Überwachung
- Einrichtung kontinuierlicher Verbesserungsprozesse zur regelmäßigen Überprüfung und Verfeinerung von Entwicklungs-, Test- und Bereitstellungspraktiken.
- Etablierung fortlaufender Überwachungs- und Warnsysteme zur Echtzeiterkennung von Anomalien und Einleitung sofortiger Korrekturmaßnahmen.
Durch die Umsetzung dieser Empfehlungen kann die Organisation ihre Incident Response weiter an den Kepner-Tregoe-Methoden ausrichten, die Resilienz erhöhen und die Wahrscheinlichkeit ähnlicher Vorfälle in Zukunft verringern. Wenn Sie jedoch eine robuste Umgebung aufbauen möchten, die darauf abzielt, diese Probleme von vornherein zu vermeiden, kontaktieren Sie uns noch heute.
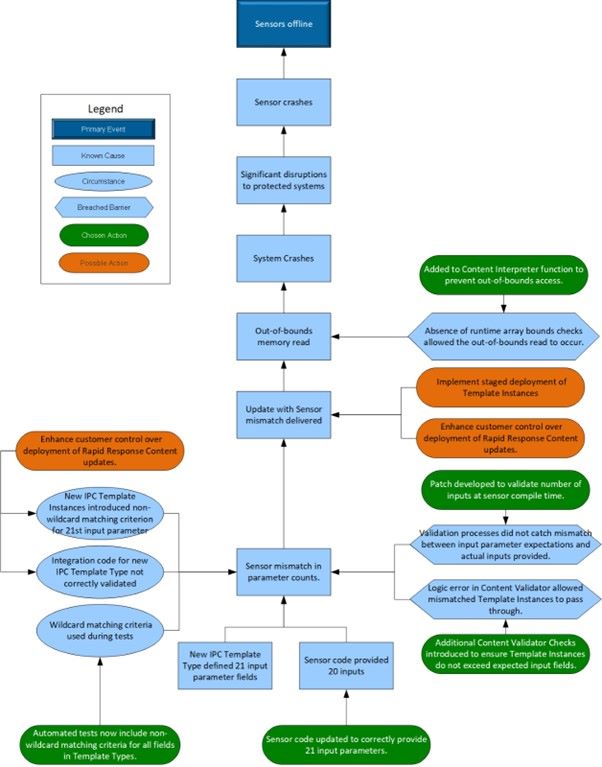
Kepner-Tregoe Incident Map


